Hive
Adding and configuring a Hive connection within Qualytics empowers the platform to build a symbolic link with your schema to perform operations like data discovery, visualization, reporting, syncing, profiling, scanning, anomaly surveillance, and more.
This documentation provides a step-by-step guide on how to add Hive as both a source and enrichment datastore in Qualytics. It covers the entire process, from initial connection setup to testing and finalizing the configuration.
By following these instructions, enterprises can ensure their Hive environment is properly connected with Qualytics, unlocking the platform's potential to help you proactively manage your full data quality lifecycle.
Let’s get started 🚀
Hive Setup Guide
Qualytics connects to Hive through the Hive JDBC driver (HiveServer2). It accesses the Hive metastore for schema and table discovery, and reads table data via HiveQL SELECT queries for profiling and scanning operations. Qualytics also identifies partition columns from Hive metastore metadata for optimized data reading.
Minimum Hive Permissions (Source Datastore)
| Permission | Purpose |
|---|---|
SELECT ON DATABASE <database_name> |
Access the database and its metadata |
SELECT ON TABLE <database_name>.* |
Read data from all tables for profiling and scanning |
Note
Qualytics does not support Hive as an enrichment datastore. You can point to a different enrichment datastore instead.
Example: Source Datastore User (Read-Only)
Replace <database_name> with your actual value.
-- Grant read access to the target database and all its tables
GRANT SELECT ON DATABASE <database_name> TO USER qualytics_read;
GRANT SELECT ON ALL TABLES IN DATABASE <database_name> TO USER qualytics_read;
Note
If using Kerberos authentication, ensure the Kerberos principal has been granted the same SELECT privileges on the target database. Configure the Kerberos principal in the connection form instead of username/password.
Info
If your Hive environment uses ZooKeeper for HiveServer2 high availability (HA), enable the ZooKeeper HA toggle in the connection form. This allows Qualytics to discover and connect to available HiveServer2 instances automatically through the ZooKeeper quorum.
Troubleshooting Common Errors
| Error | Likely Cause | Fix |
|---|---|---|
User is not allowed to impersonate |
The HiveServer2 proxy user configuration does not allow the Qualytics user | Add the Qualytics user to the hadoop.proxyuser.<hive_user>.users property in core-site.xml |
Permission denied: user does not have SELECT privilege |
The user lacks SELECT on the target database or table |
Run GRANT SELECT ON DATABASE <database_name> TO USER <user> |
GSS initiate failed (Kerberos) |
Kerberos ticket is expired, the principal is incorrect, or the KDC is unreachable | Verify the Kerberos principal, ensure the keytab is valid, and check KDC connectivity |
Could not open client transport |
HiveServer2 is not reachable or the port (default 10000) is incorrect | Verify the host, port, and that HiveServer2 is running |
Database does not exist |
The database name (schema) in the connection form is incorrect | Verify the database name with SHOW DATABASES in HiveQL |
Detailed Troubleshooting Notes
Authentication Errors
The error GSS initiate failed (Kerberos) or Could not open client transport indicates an authentication or transport problem.
Common causes:
- Kerberos ticket expired — the Kerberos ticket has expired and needs to be renewed with
kinit. - Wrong principal — the Kerberos principal in the connection form does not match the one configured in the Hive server.
- KDC unreachable — the Key Distribution Center (KDC) is not reachable from the Qualytics server.
- HiveServer2 not running — the HiveServer2 process is not started or has crashed.
Note
If using basic authentication (username/password), ensure HiveServer2 is configured to accept password-based authentication (hive.server2.authentication=CUSTOM or LDAP).
Permission Errors
The error Permission denied: user does not have SELECT privilege means the user authenticated successfully but lacks the necessary Hive grants.
Common causes:
- Missing
SELECTon database — the user does not haveSELECTon the target database. - Missing
SELECTon table — the user has database-level access but not table-level access. - Ranger/Sentry policy — if Apache Ranger or Sentry is enabled, permissions are managed through policies rather than Hive
GRANTstatements.
Connection Errors
The error Could not open client transport or User is not allowed to impersonate indicates a transport or proxy user issue.
Common causes:
- HiveServer2 not reachable — the host or port (default 10000) is incorrect.
- Proxy user not allowed — the
hadoop.proxyuser.<hive_user>.usersproperty incore-site.xmldoes not include the Qualytics user. - SSL required — HiveServer2 requires SSL but the connection is not configured for it.
Tip
Start by confirming credentials and Kerberos configuration are valid (authentication errors), then verify Hive grants or Ranger policies (permission errors), and finally check HiveServer2 connectivity (connection errors).
Add a Source Datastore
A source datastore is a storage location used to connect to and access data from external sources. Hive is an example of a source datastore, specifically a type of JDBC datastore that supports connectivity through the JDBC API. Configuring the JDBC datastore enables the Qualytics platform to access and perform operations on the data, thereby generating valuable insights.
Step 1: Log in to your Qualytics account and click on the Add Source Datastore button located at the top-right corner of the interface.
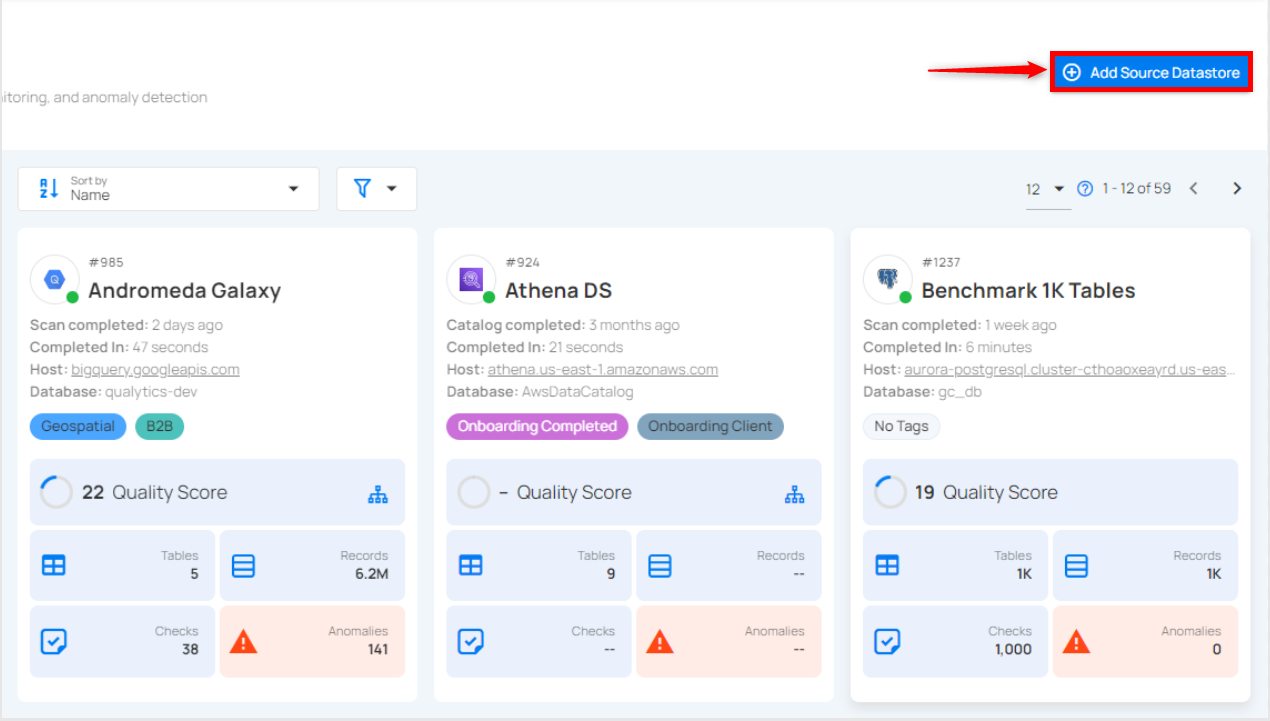
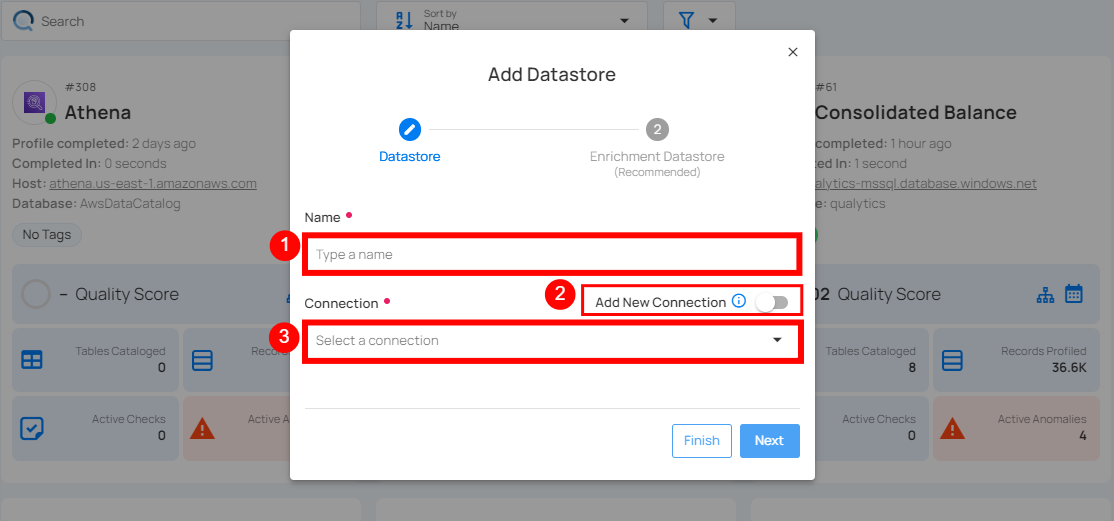
Step 2: A modal window- Add Datastore will appear, providing you with the options to connect a datastore.
| REF. | FIELDS | ACTIONS |
|---|---|---|
| 1. | Name (Required) | Specify the datastore name (e.g., This name will appear on the datastore cards) |
| 2. | Toggle Button | Toggle ON to create a new source datastore from scratch, or toggle OFF to reuse credentials from an existing connection. |
| 3. | Connector (Required) | Select Hive from the dropdown list. |
Option I: Create a Source Datastore with a new Connection
If the toggle for Add New connection is turned on, then this will prompt you to add and configure the source datastore from scratch without using existing connection details.
Step 1: Select the Hive connector from the dropdown list and add the connection details.
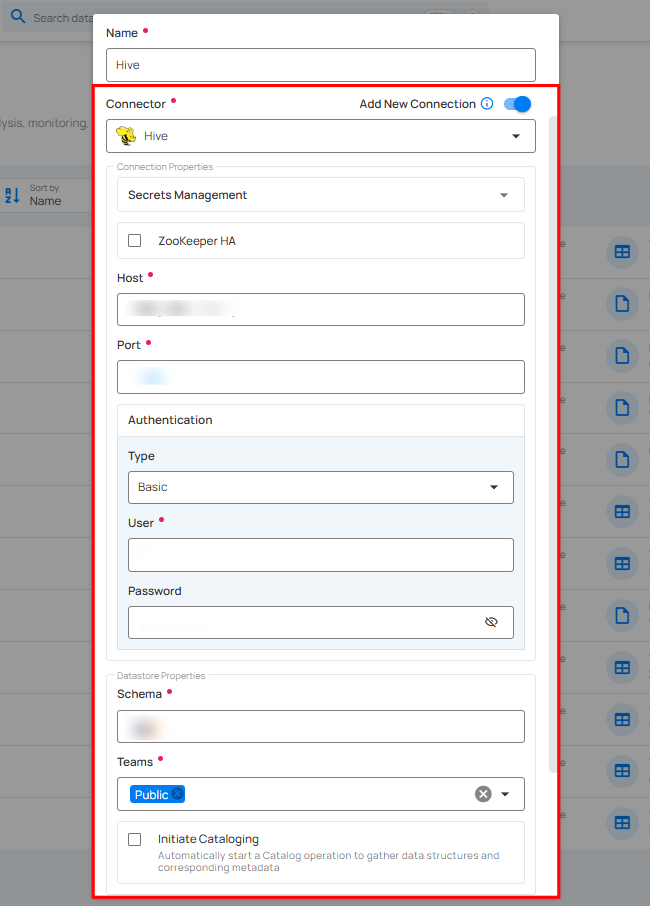
Secrets Management: This is an optional connection property that allows you to securely store and manage credentials by integrating with HashiCorp Vault and other secret management systems. Toggle it ON to enable Vault integration for managing secrets.
Note
After configuring HashiCorp Vault integration, you can use ${key} in any Connection property to reference a key from the configured Vault secret. Each time the Connection is initiated, the corresponding secret value will be retrieved dynamically.
| REF | FIELDS | ACTIONS |
|---|---|---|
| 1. | Login URL | Enter the URL used to authenticate with HashiCorp Vault. |
| 2. | Credentials Payload | Input a valid JSON containing credentials for Vault authentication. |
| 3. | Token JSONPath | Specify the JSONPath to retrieve the client authentication token from the response (e.g., $.auth.client_token). |
| 4. | Secret URL | Enter the URL where the secret is stored in Vault. |
| 5. | Token Header Name | Set the header name used for the authentication token (e.g., X-Vault-Token). |
| 6. | Data JSONPath | Specify the JSONPath to retrieve the secret data (e.g., $.data). |
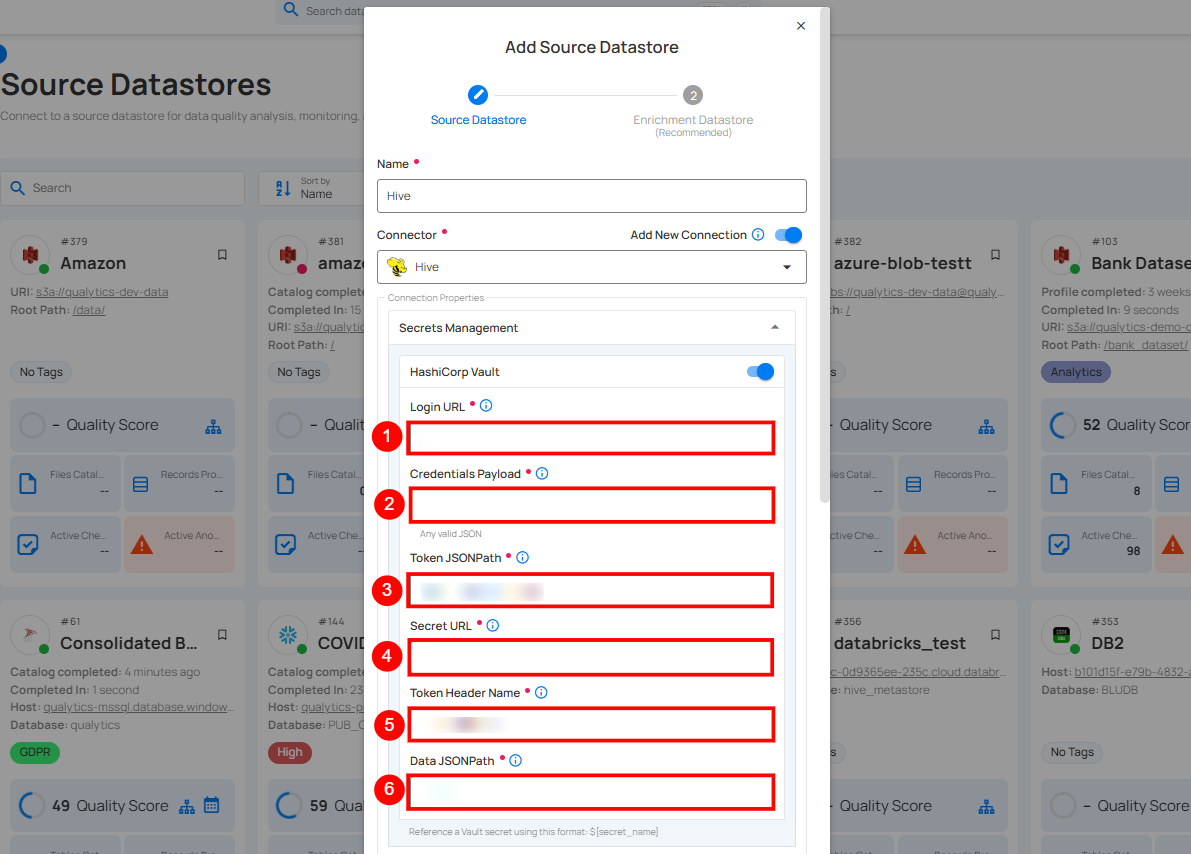
Step 2: The configuration form will expand, requesting credential details before establishing the connection.
| REF. | FIELDS | ACTIONS |
|---|---|---|
| 1. | Host(Required) | Get Hostname from your Hive account and add it to this field. |
| 2. | Port(Required) | Specify the Port number. |
| 3. | Authentication | You can choose between Basic Authentication and Kerberos Authentication for validating and securing the connection to your Hive instance. Basic Authentication: This method uses a username and password combination for authentication. It is a straightforward method where the user's credentials are directly used to access Hive.
|
| 4. | Schema(Required) | Define the schema within the database that should be used. |
| 5. | Teams(Required) | Select one or more teams from the dropdown to associate with this source datastore. |
| 6. | Initiate Sync (Optional) | Tick the checkbox to automatically perform sync operation on the configured source datastore to detect new, changed, or removed containers and fields. |
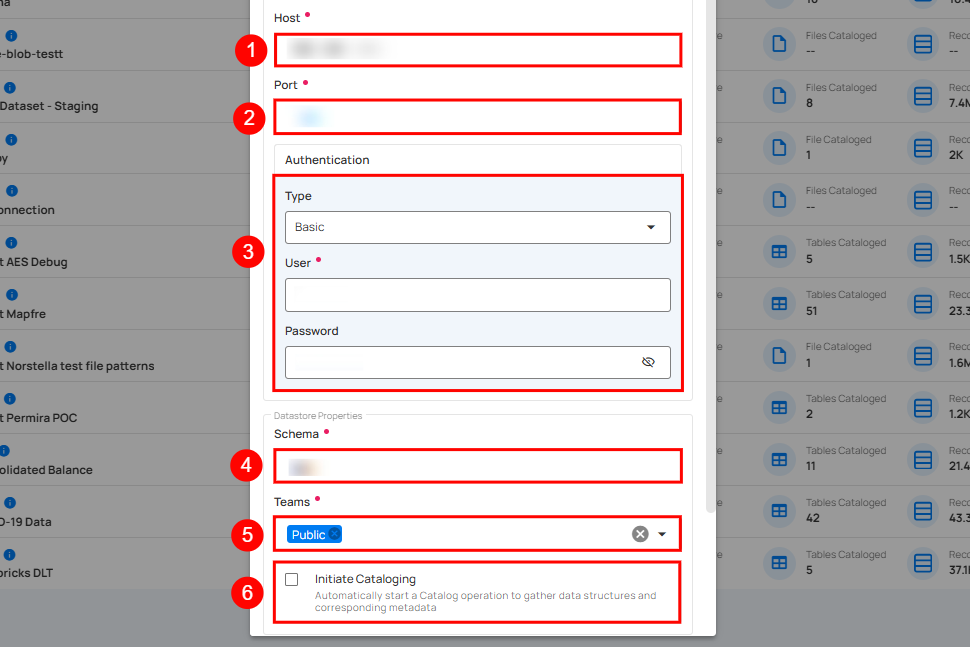
Step 3: After adding the source datastore details, click on the Test Connection button to check and verify its connection.
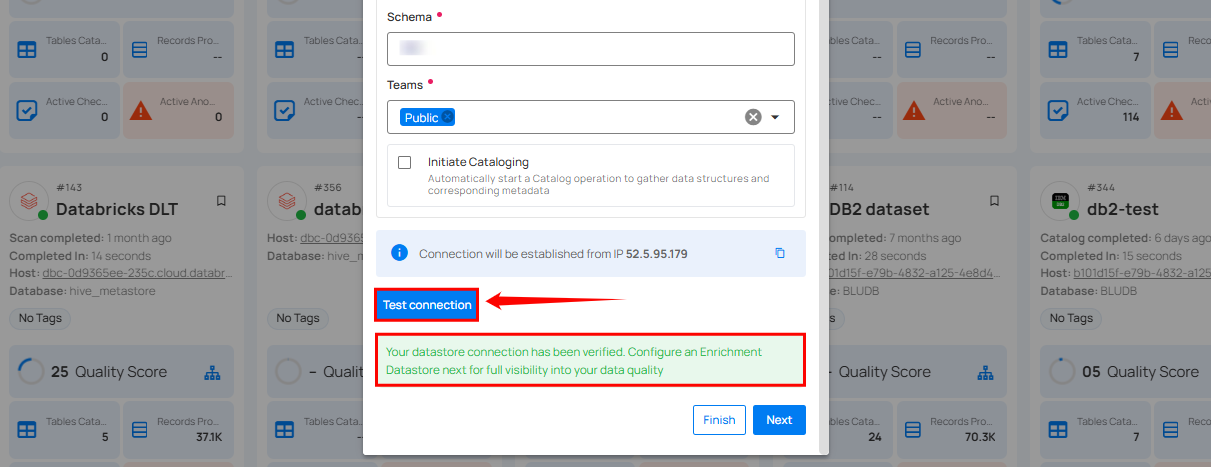
If the credentials and provided details are verified, a success message will be displayed indicating that the connection has been verified.
Option II: Use an Existing Connection
If the toggle for Add new connection is turned off, then this will prompt you to configure the source datastore using the existing connection details.
Step 1: Select a connection to reuse existing credentials.
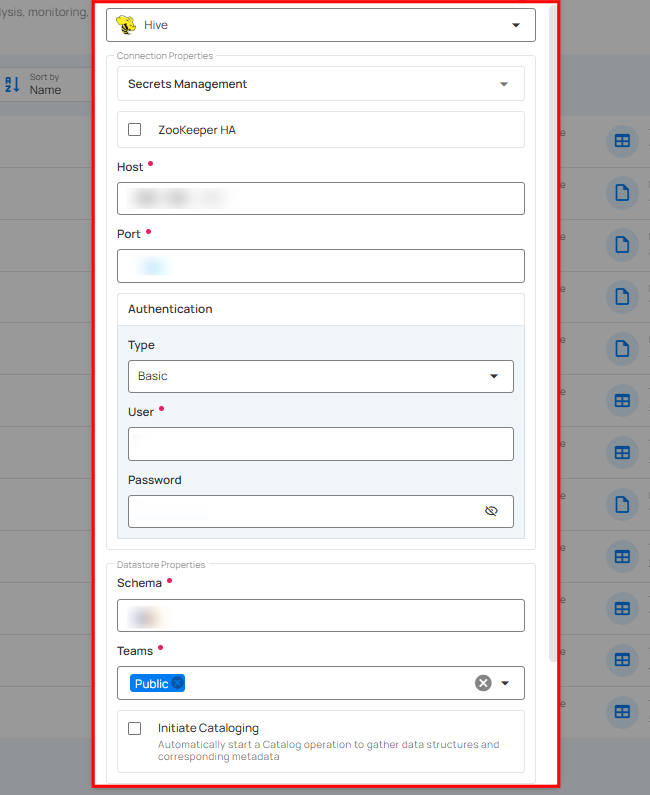
Note
If you are using existing credentials, you can only edit the details such as Database, Schema, Teams, and Initiate Sync.
Step 2: Click on the Test Connection button to verify the existing connection details. If connection details are verified, a success message will be displayed.
Note
Clicking on the Finish button will create the source datastore and bypass the enrichment datastore configuration step.
Tip
It is recommended to click on the Next button, which will take you to the enrichment datastore configuration page.
Add Enrichment Datastore
Once you have successfully tested and verified your source datastore connection, you have the option to add the enrichment datastore (recommended). The enrichment datastore is used to store the analyzed results, including any anomalies and additional metadata in tables. This setup provides full visibility into your data quality, helping you manage and improve it effectively.
Warning
Qualytics does not support the Hive connector as an enrichment datastore, but you can point to a different enrichment datastore.
Step 1: Whether you have added a source datastore by creating a new datastore connection or using an existing connection, click on the Next button to start adding the Enrichment Datastore.
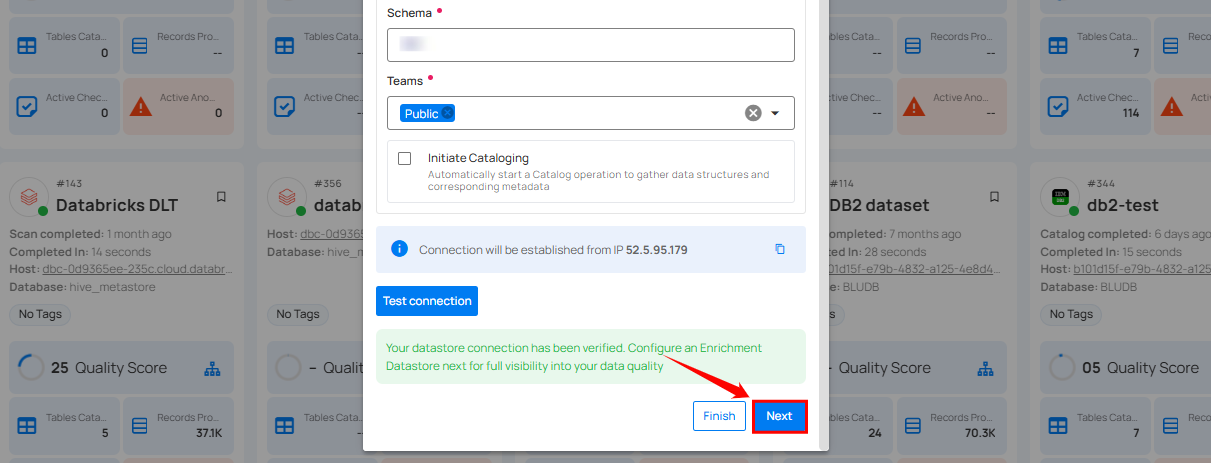
Step 2: A modal window- Link Enrichment Datastore will appear, providing you with the options to configure an enrichment datastore.
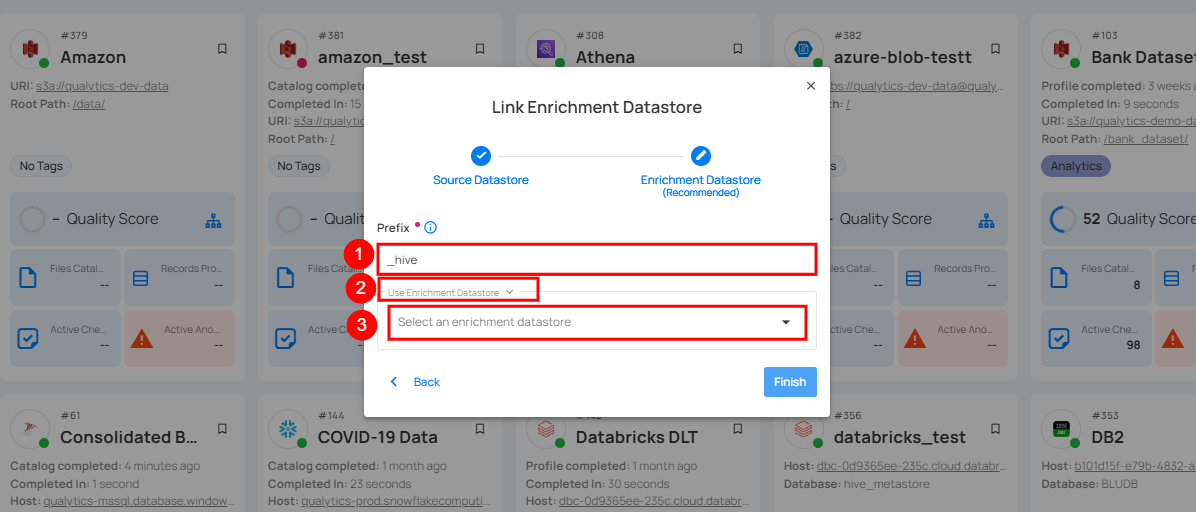
| REF. | FIELDS | ACTIONS |
|---|---|---|
| 1. | Prefix (Required) | Add a prefix name to uniquely identify tables/files when Qualytics writes metadata from the source datastore to your enrichment datastore. |
| 2. | Caret Down Button | Click the caret down to select either Use Enrichment Datastore or Add Enrichment Datastore. |
| 3. | Enrichment Datastore | Select an enrichment datastore from the dropdown list. |
Option I: Create an Enrichment Datastore with a new Connection
If the toggle Add new connection is turned on, then this will prompt you to add and configure the enrichment datastore from scratch without using an existing enrichment datastore and its connection details.
Step 1: Click on the caret button and select Add Enrichment Datastore.
![]()
A modal window Link Enrichment Datastore will appear. Enter the following details to create an enrichment datastore with a new connection.
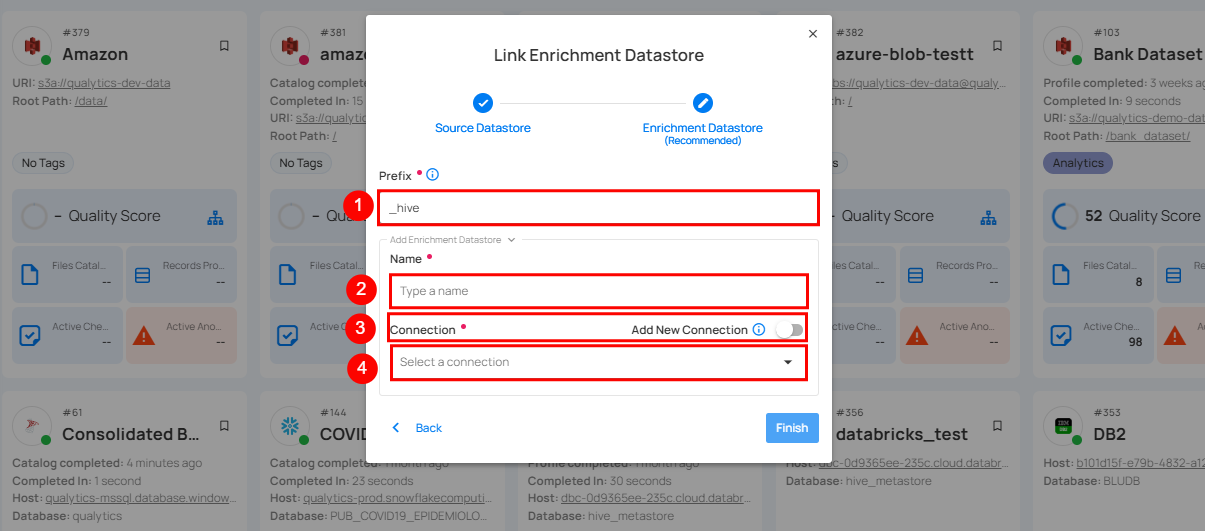
| REF. | FIELDS | ACTIONS |
|---|---|---|
| 1. | Prefix | Add a prefix name to uniquely identify tables/files when Qualytics writes metadata from the source datastore to your enrichment datastore. |
| 2. | Name | Give a name for the enrichment datastore. |
| 3. | Toggle Button for add new connection | Toggle ON to create a new enrichment from scratch or toggle OFF to reuse credentials from an existing connection. |
| 4. | Connector | Select a datastore connector from the dropdown list. |
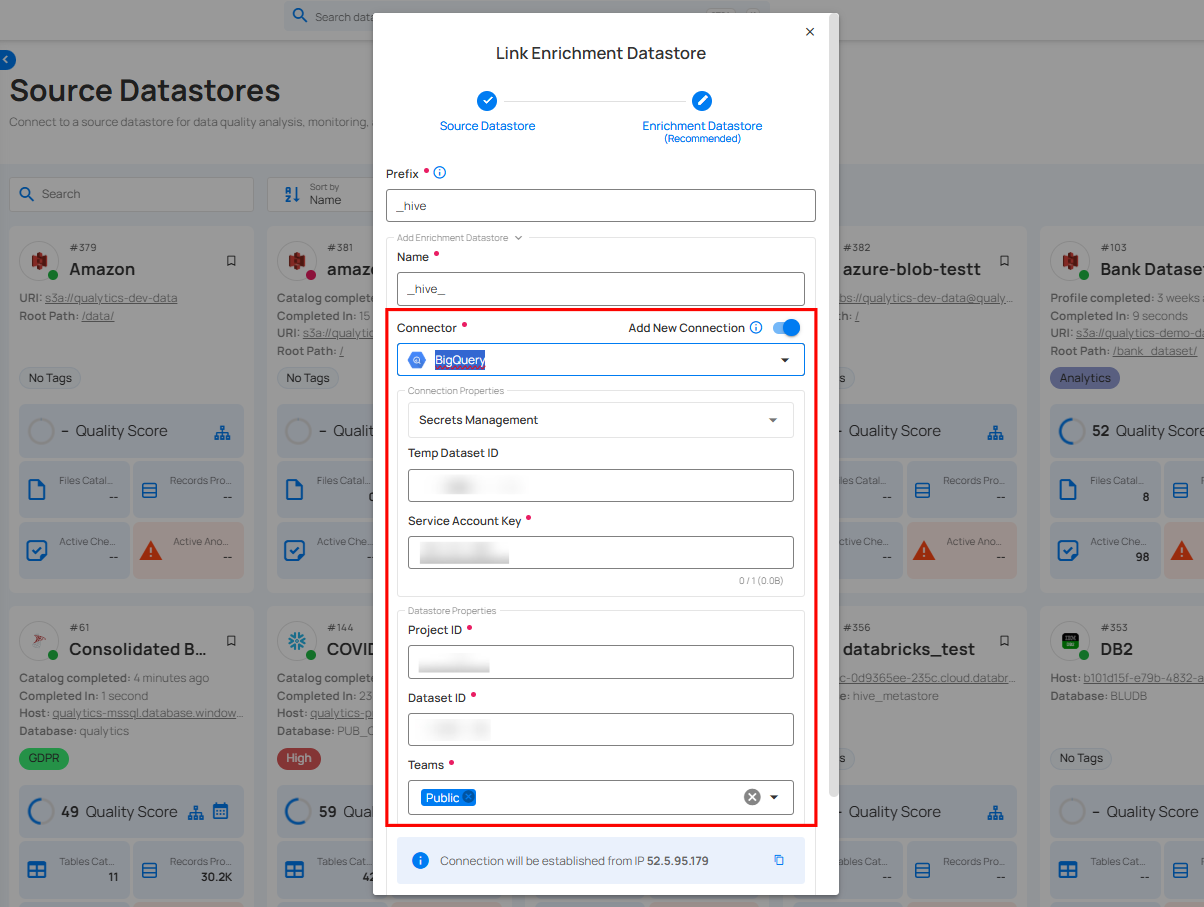
Step 2: Add connection details for your selected enrichment datastore connector.
Note
Qualytics does not support Hive as an enrichment datastore. Instead, you can select a different enrichment datastore for this purpose. For demonstration purposes, we are using BigQuery as the enrichment datastore. You can use any other JDBC or DFS datastore of your choice for the enrichment datastore configuration.
Step 3: Click on the Test Connection button to verify the selected enrichment datastore connection. If the connection is verified, a flash message will indicate that the connection with the datastore has been successfully verified.
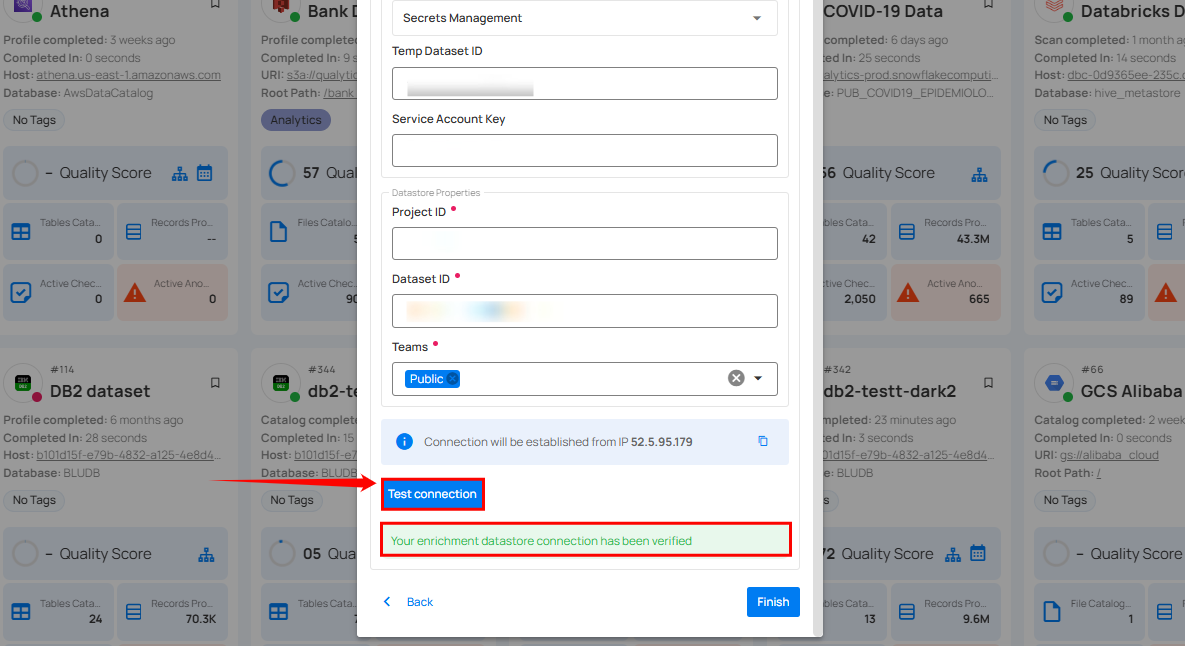
Step 4: Click on the Finish button to complete the configuration process.
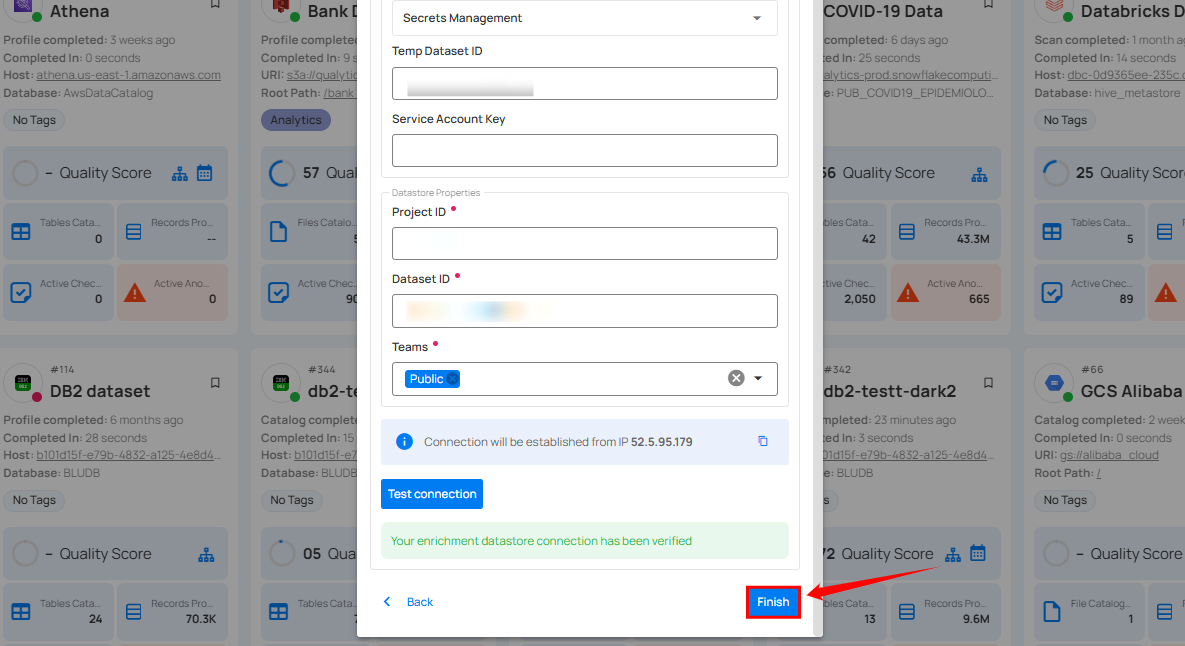
When the configuration process is finished, a modal will display a success message indicating that your datastore has been successfully added.
Close the Success dialog and the page will automatically redirect you to the Source Datastore Details page where you can perform data operations on your configured source datastore.
Option II: Use an Existing Connection
If the Use enrichment datastore option is selected from the caret button, you will be prompted to configure the datastore using existing connection details.
Step 1: Click on the caret button and select Use Enrichment Datastore.
![]()
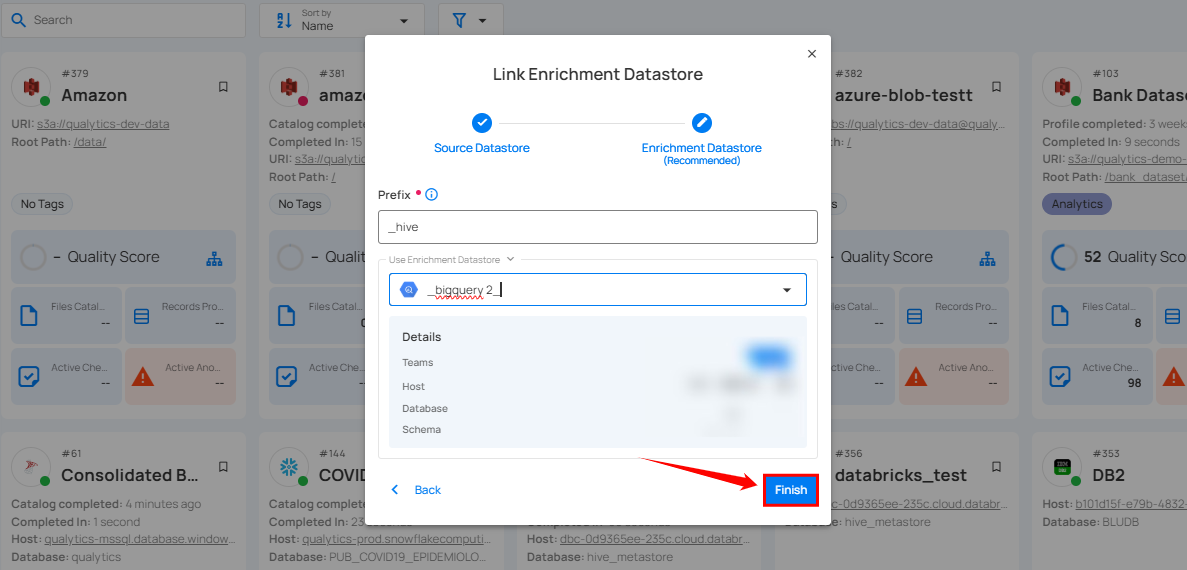
Step 2: A modal window Link Enrichment Datastore will appear. Add a prefix name and select an existing enrichment datastore from the dropdown list.
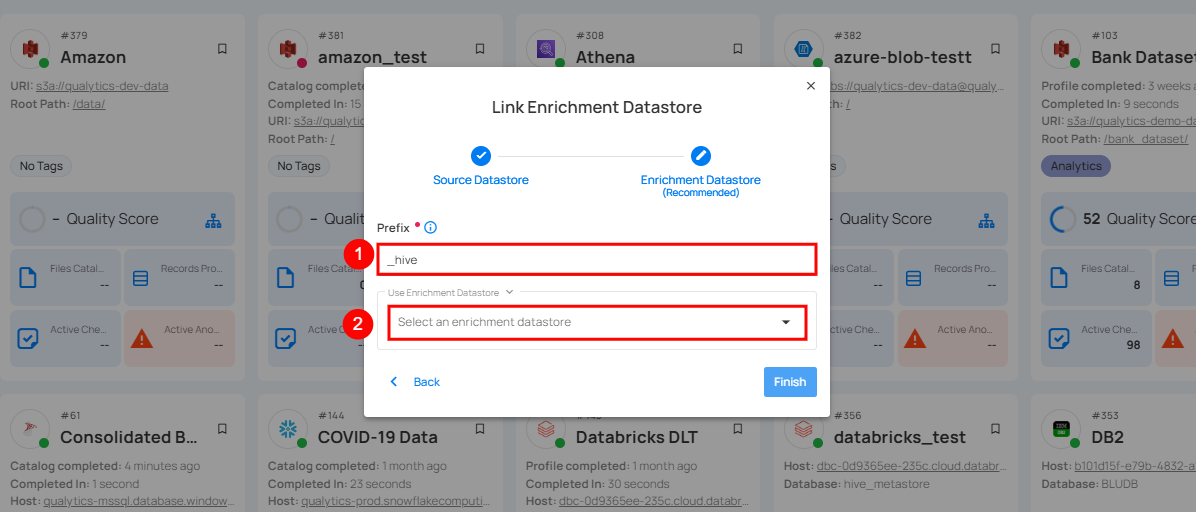
| REF. | FIELDS | ACTIONS |
|---|---|---|
| 1. | Prefix (Required) | Add a prefix name to uniquely identify tables/files when Qualytics writes metadata from the source datastore to your enrichment datastore. |
| 2. | Enrichment Datastore | Select an enrichment datastore from the dropdown list. |
Step 3: After selecting an existing enrichment datastore connection, you will view the following details related to the selected enrichment:
- Teams: The team associated with managing the enrichment datastore is based on the role of public or private. Example- Marked as Public means that this datastore is accessible to all the users.
- Host: This is the server address where the enrichment datastore instance is hosted. It is the endpoint used to connect to the enrichment datastore environment.
- Database: Refers to the specific database within the enrichment datastore environment where the data is stored.
- Schema: The schema used in the enrichment datastore. The schema is a logical grouping of database objects (tables, views, etc.). Each schema belongs to a single database.
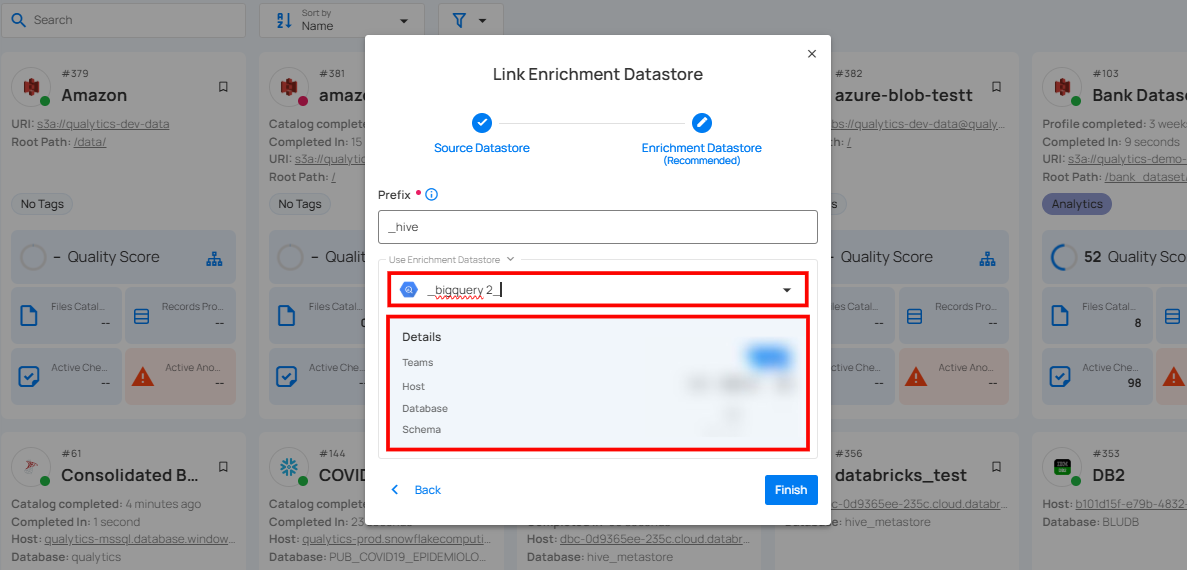
Step 4: Click on the Finish button to complete the configuration process for the existing enrichment datastore.
When the configuration process is finished, a modal will display a success message indicating that your data has been successfully added.
Close the success message and you will be automatically redirected to the Source Datastore Details page where you can perform data operations on your configured source datastore.
API Payload Examples
This section provides detailed examples of API payloads to guide you through the process of creating and managing datastores using Qualytics API.
Each example includes endpoint details, sample payloads, and instructions on how to replace placeholder values with actual data relevant to your setup.
Creating a Datastore
This section provides a sample payload for creating a datastore. Replace the placeholder values with actual data relevant to your setup.
Endpoint (Post)
/api/datastores (post)
{
"name": "your_datastore_name",
"teams": ["Public"],
"database": "hive_database",
"schema": "hive_schema",
"enrich_only": false,
"trigger_catalog": true,
"connection": {
"name": "your_connection_name",
"type": "hive",
"host": "hive_host",
"port": "hive_port",
"username": "hive_username",
"password": "hive_password",
"parameters": {
"zookeeper": false
}
}
}
# Step 1: Create a Connection
qualytics connections create \
--type hive \
--name "your_connection_name" \
--host ${HIVE_HOST} \
--port 10000 \
--username ${HIVE_USER} \
--password ${HIVE_PASSWORD}
# Step 2: Create a Source Datastore
qualytics datastores create \
--name "your_datastore_name" \
--connection-name "your_connection_name" \
--schema default
Linking Datastore to an Enrichment Datastore through API
Endpoint (Patch)
/api/datastores/{datastore-id}/enrichment/{enrichment-id} (patch)