Computed Fields
Computed Fields allow you to enhance data analysis by applying dynamic transformations directly to your data. These fields let you create new data points, perform calculations, and customize data views based on your specific needs, ensuring your data is both accurate and actionable.
Let's get started 🚀
Add Computed Fields
Step 1: Log in to Your Qualytics Account, navigate to the side menu, and select the source datastore where you want to create a computed field.


Step 2: Select the Container within the chosen datastore where you want to create the computed field. This container holds the data to which the new computed field will be applied, enabling you to enhance your data analysis within that specific datastore.
For demonstration purposes, we have selected the Bank Dataset-Staging source datastore and the bank_transactions_.csv container within it to create a computed field.


Step 3: After selecting the container, click on the Add button and select Computed Field from the dropdown menu to create a new computed field.


A modal window will appear, allowing you to enter the details for your computed field.


Step 4: Enter the Name for the computed field, select Transformation Type from the dropdown menu, and optionally add Additional Metadata.
| REF. | FIELDS | ACTION |
|---|---|---|
| 1. | Field Name (Required) | Add a unique name for your computed field. |
| 2. | Transformation Type (Required) | The type of transformation you want to apply from the available options. |
| 3. | Additional Metadata (Optional) | Enhance the computed field definition by setting custom metadata. Click the plus icon (+) to open the metadata input form and add key-value pairs. |


Info
Transformations are changes made to data, like converting formats, doing calculations, or cleaning up fields. In Qualytics, you can use transformations to meet specific needs, such as cleaning entity names, converting formatted numbers, or applying custom expressions. With various transformation types available, Qualytics enables you to customize your data directly within the platform, ensuring it’s accurate and ready for analysis.
| Transformation Types | Purpose | Reference |
|---|---|---|
| Cleaned Entity Name | Removes business signifiers (such as 'Inc.' or 'Corp') from an entity name. | See here |
| Convert Formatted Numeric | Removes formatting (such as parentheses for denoting negatives or commas as delimiters) from values that represent numeric data, converting them into a numerically typed field. | See here |
| Custom Expression | Allows you to create a new field by applying any valid Spark SQL expression to one or more existing fields. | See here |


Step 5: After selecting the appropriate Transformation Type, click the Save button.


Step 6: After clicking on the Save button, your computed field is created and a success flash message will display saying The computed field has been successfully created.


You can find your computed field by clicking on the dropdown arrow next to the container you selected when creating the computed field.


Computed Fields Details
Totals
1. Quality Score: This provides a comprehensive assessment of the overall health of the data, factoring in multiple checks for accuracy, consistency, and completeness. A higher score, closer to 100, indicates optimal data quality with minimal issues or errors detected. A lower score may highlight areas that require attention and improvement.
2. Sampling: This shows the percentage of data that was evaluated during profiling. A sampling rate of 100% indicates that the entire dataset was analyzed, ensuring a complete and accurate representation of the data’s quality across all records, rather than just a partial sample.
3. Completeness: This metric measures how fully the data is populated without missing or null values. A higher completeness percentage means that most fields contain the necessary information, while a lower percentage indicates data gaps that could negatively impact downstream processes or analysis.
4. Active Checks: This refers to the number of ongoing quality checks being applied to the dataset. These checks monitor aspects such as format consistency, uniqueness, and logical correctness. Active checks help maintain data integrity and provide real-time alerts about potential issues that may arise.
5. Active Anomalies: This tracks the number of anomalies or irregularities detected in the data. These could include outliers, duplicates, or inconsistencies that deviate from expected patterns. A count of zero indicates no anomalies, while a higher count suggests that further investigation is needed to resolve potential data quality issues.


Profile
This provides detailed insights into the characteristics of the field, including its type, distinct values, and length. You can use this information to evaluate the data's uniqueness, length consistency, and complexity.
| No | Profile | Description |
|---|---|---|
| 1 | Declared Type | Indicates whether the type is declared by the source or inferred. |
| 2 | Distinct Values | Count of distinct values observed in the dataset. |
| 3 | Min Length | Shortest length of the observed string values or lowest value for numerics. |
| 4 | Max Length | Greatest length of the observed string values or highest value for numerics. |
| 5 | Mean | Mathematical average of the observed numeric values. |
| 6 | Median | The median of the observed numeric values. |
| 7 | Standard Deviation | Measure of the amount of variation in observed numeric values. |
| 8 | Kurtosis | Measure of the ‘tailedness’ of the distribution of observed numeric values. |
| 9 | Skewness | Measure of the asymmetry of the distribution of observed numeric values. |
| 10 | Q1 | The first quartile; the central point between the minimum and the median. |
| 11 | Q3 | The third quartile; the central point between the median and the maximum. |
| 12 | Sum | Total sum of all observed numeric values. |


You can hover over the (i) button to view the native field properties, which provide detailed information such as the field's type (numeric), size, decimal digits, and whether it allows null values.


Last Profile
The Last Profile timestamp helps users understand how up to date the field is. When you hover over the time indicator shown on the right side of the Last Profile label (e.g., "8 months ago"), a tooltip displays the complete date and time the field was last profiled.


This visibility ensures better context for interpreting profile metrics like mean, completeness, and anomalies.
Manage Tags in field details
Tags can now be directly managed in the field profile within the Explore section. Simply access the Field Details panel to create, add, or remove tags, enabling more efficient and organized data management.
Step 1: Log in to your Qualytics account and click the Explore button on the left side panel of the interface.


Step 2: Click on the Profiles tab and select fields.


Step 3: Click on the specific field that you want to manage tags.


A Field Details modal window will appear. Click on the plus button (+) to assign tags to the selected field.


Step 4: You can also create the new tag by clicking on the ➕ button.


A modal window will appear, providing the options to create the tag. Enter the required values to get started.


For more information on creating tags, refer to the Add Tag section.
View Team
By hovering over the information icon, users can view the assigned teams for enhanced collaboration and data transparency.


Filter and Sort Fields
Filter and Sort options allow you to organize your fields by various criteria, such as Name, Checks, Completeness, Created Date, and Tags. You can also apply filters to refine your list of fields based on Type and Tags
Sort
You can sort your checks by Active Anomalies, Active Checks, Completeness, Created Date, Name, Quality Score, and Type to easily organize and prioritize them according to your needs.


| No | Sort By | Description |
|---|---|---|
| 1 | Active Anomalies | Sorts fields based on the number of currently active anomalies detected. |
| 2 | Active Checks | Sorts fields by the number of active validation checks applied. |
| 3 | Completeness | Sorts fields based on their data completeness percentage. |
| 4 | Created Date | Sorts fields by the date they were created, showing the newest or oldest fields first. |
| 5 | Name | Sorts fields alphabetically by their names. |
| 6 | Quality Score | Sorts fields based on their quality score, indicating the reliability of the data in the field. |
| 7 | Type | Sorts fields based on their data type (e.g., string, boolean, etc.). |


Whatever sorting option is selected, you can arrange the data either in ascending or descending order by clicking the caret button next to the selected sorting criteria.
![]()
![]()
Filter
You can filter your fields based on values like Type and Tag to easily organize and prioritize them according to your needs.
Info
Users can search across all filter inputs using typos, partial terms, or abbreviations.
The system intelligently matches relevant results, making it easier to find what they need without exact inputs.
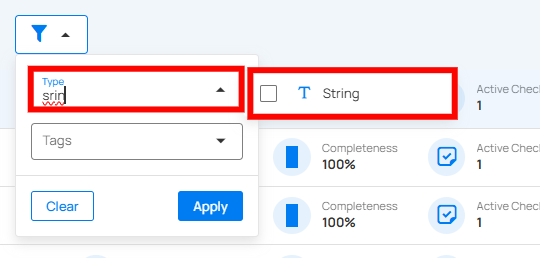


| No | Filter | Description |
|---|---|---|
| 1 | Type | Filters fields based on the data type (e.g., string, boolean, date, etc.). |
| 2 | Tag | Tag Filter displays only the tags associated with the currently visible items, along with their color icon, name, type, and the number of matching records. Selecting one or more tags refines the list based on your selection. If no matching items are found, a No option found message is displayed. |
Types of Transformations
Cleaned Entity Name
This transformation removes common business signifiers from entity names, making your data cleaner and more uniform.
Options for Cleaned Entity Name
| REF. | FIELDS | ACTIONS |
|---|---|---|
| 1. | Drop from Suffix | Add a unique name for your computed field. |
| 2. | Drop from Prefix | Removes specified terms from the beginning of the entity name. |
| 3. | Drop from Interior | Removes specified terms from the beginning of the entity name. |
| 4. | Additional Terms to Drop (Custom) | Allows you to specify additional terms that should be dropped from the entity name. |
| 5. | Terms to Ignore (Custom) | Designate terms that should be ignored during the cleaning process. |
Example for Cleaned Entity Name
| Example | Input | Transformation | Output |
|---|---|---|---|
| 1 | "TechCorp, Inc." | Drop from Suffix: "Inc." | "TechCorp" |
| 2 | "Global Services Ltd." | Drop from Prefix: "Global" | "Services Ltd." |
| 3 | "Central LTD & Finance Co." | Drop from Interior: "LTD" | "Central & Finance Co." |
| 4 | "Eat & Drink LLC" | Additional Terms to Drop: "LLC", "&" | "Eat Drink" |
| 5 | "ProNet Solutions Ltd." | Terms to Ignore: "Ltd." | "ProNet Solutions" |
Convert Formatted Numeric
This transformation converts formatted numeric values into a plain numeric format, stripping out any characters like commas or parentheses that are not numerically significant.
Example for Convert Formatted Numeric
| Example | Input | Transformation | Output |
|---|---|---|---|
| 1 | "$1,234.56" | Remove non-numeric characters: ",", "$" | "1234.56" |
| 2 | "(2020)" | Remove non-numeric characters: "(", ")" | "-2020" |
| 3 | "100%" | Remove non-numeric characters: "%" | "100" |
Custom Expression
Enables the creation of a field based on a custom computation using Spark SQL. This is useful for applying complex logic or transformations that are not covered by other types.
Using Custom Expression:
You can combine multiple fields, apply conditional logic, or use any valid Spark SQL functions to derive your new computed field.
Example: To create a field that sums two existing fields, you could use the expression SUM(field1, field2).
Advanced Example: You need to ensure that a log of leases has no overlapping dates for an asset but your data only captures a single lease's details like
| LeaseID | AssetID | Lease_Start | Lease_End |
|---|---|---|---|
| 1 | 42 | 1/1/2025 | 2/1/2026 |
| 2 | 43 | 1/1/2025 | 2/1/2026 |
| 3 | 42 | 1/1/2026 | 2/1/2026 |
| 4 | 43 | 2/2/2026 | 2/1/2027 |
You can see in this example that Lease 1 has overlapping dates with Lease 3 for the same Asset. This can be difficult to detect without a full transformation of the data. However, we can accomplish our goal easily with a Computed Field. We'll simply add a Computed Field to our table named "Next_Lease_Start" and define it with the following custom expression so that our table will now hold the new field and render it as shown below.
LEAD(Lease_Start, 1) OVER (PARTITION BY AssetID ORDER BY Lease_Start)
| LeaseID | AssetID | Lease_Start | Lease_End | Next_Lease_Start |
|---|---|---|---|---|
| 1 | 42 | 1/1/2025 | 2/1/2026 | 1/1/2026 |
| 2 | 43 | 1/1/2025 | 2/1/2026 | 2/2/2026 |
| 3 | 42 | 1/1/2026 | 2/1/2026 | |
| 4 | 43 | 2/2/2026 | 2/1/2027 |
Now you can author a Quality Check stating that Lease_End should always be less than "Next_Lease_Start" to catch any errors of this type. In fact, Qualytics will automatically infer that check for you at Level 3 Inference!
More Examples for Custom Expression
| Example | Input Fields | Custom Expression | Output |
|---|---|---|---|
| 1 | field1 = 10, field2 = 20 |
SUM(field1, field2) |
30 |
| 2 | salary = 50000, bonus = 5000 |
salary + bonus |
55000 |
| 3 | hours = 8, rate = 15.50 |
hours * rate |
124 |
| 4 | status = 'active', score = 85 |
CASE WHEN status = 'active' THEN score ELSE 0 END |
85 |