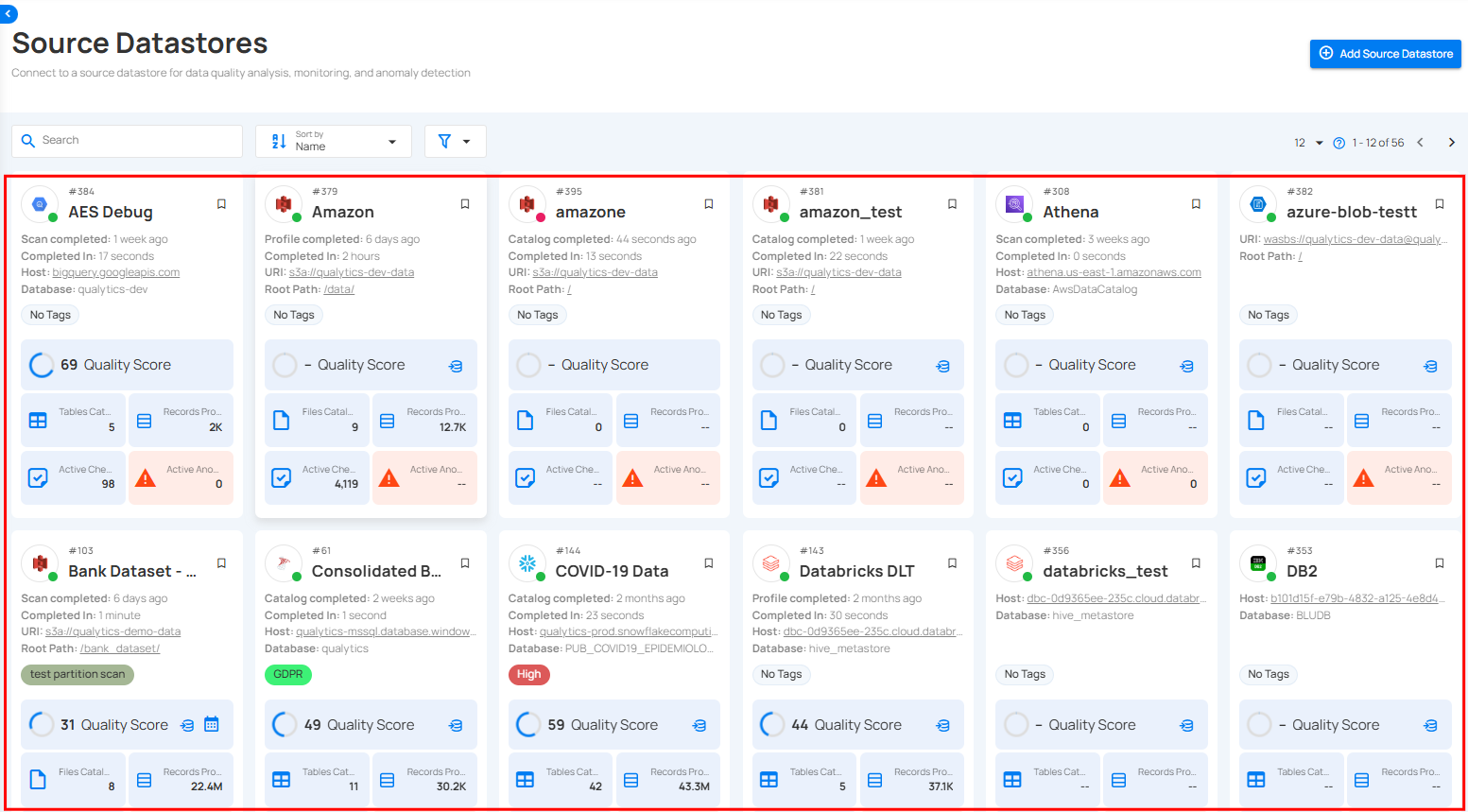
Source Datastore
Qualytics connects to source datastores using "Datastores," a framework that enables organizations to:
-
Connect with a wide range of source datastores through verified connectors.
-
Support both traditional databases and modern object storage.
-
Profile and monitor structured data across systems.
-
Ensure secure and fast access to data.
-
Scale data quality operations across platforms.
-
Manage data quality centrally across all sources.
These source datastore integrations ensure comprehensive quality management across your entire data landscape, regardless of where your data resides.
Understanding Datastores
A Datastore in Qualytics represents any structured source datastore, such as:
-
Relational databases (RDBMS)
-
Raw file formats like CSV, XLSX, JSON, Avro, or Parquet
-
Cloud storage platforms like AWS S3, Azure Blob Storage, or GCP Cloud Storage
Qualytics integrates with these source datastores through a layered architecture:

Configuring Source Datastores
Configure your source datastores in Qualytics by connecting them through a new datastore.
Step 1: Log in to your Qualytics account and click on the Add Source Datastore button located at the top-right corner of the interface.
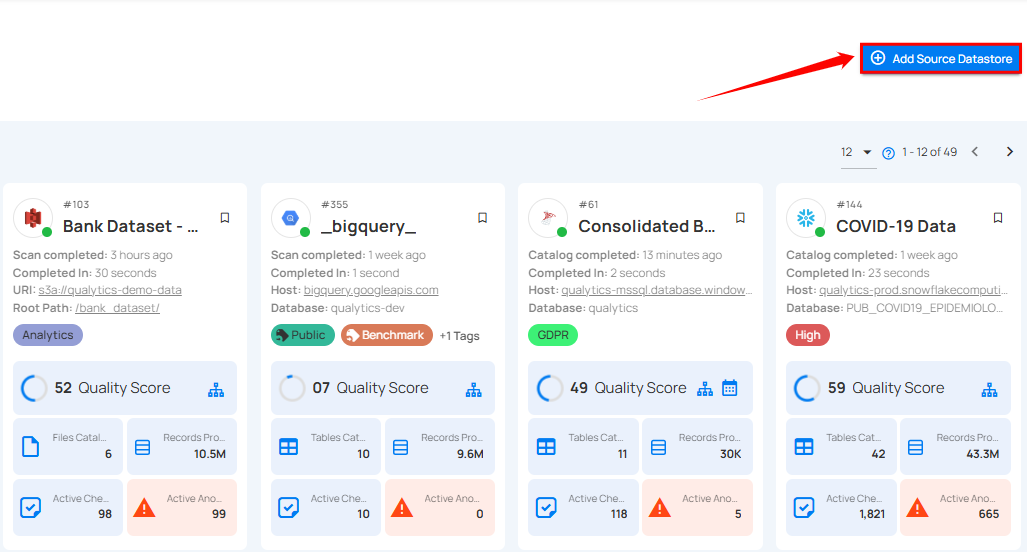
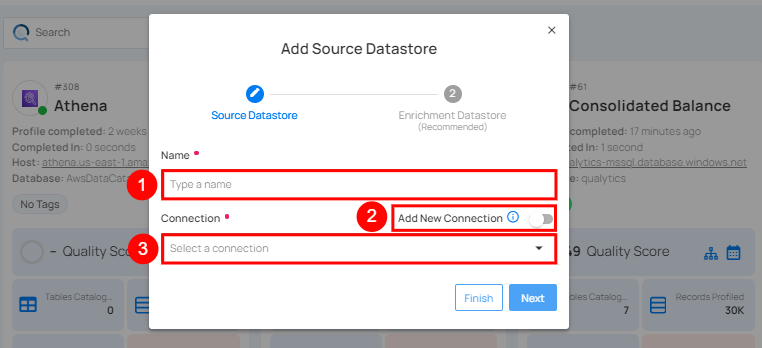
Step 2: A modal window, Add Datastore, will appear, providing you with the options to connect a datastore.
| REF. | FIELDS | ACTIONS |
|---|---|---|
| 1. | Name | Specify the name of the datastore (e.g., the specified name will appear on the datastore cards). |
| 2. | Toggle Button | Toggle on to create a new source datastore from scratch, or toggle off to reuse credentials from an existing connection. |
| 3. | Connector | Select Any source datastore from the dropdown list. |
Available Datastore Connectors
Qualytics provides verified connectors for the following source datastores:
Tip
Want to check which datastores have Enrichment support? See the Supported Enrichment Datastores
| No. | Source Datastores |
|---|---|
| 1. | Amazon Redshift |
| 2. | Amazon S3 |
| 3. | Athena |
| 4. | Azure Datalake Storage (ABFS) |
| 5. | Big Query |
| 6. | Databricks |
| 7. | DB2 |
| 8. | Dremio |
| 9. | Fabric Analytics |
| 10. | Google Cloud Storage |
| 11. | Hive |
| 12. | MariaDB |
| 13. | Microsoft SQL Server |
| 14. | MySQL |
| 15. | Oracle |
| 16. | PostgreSQL |
| 17. | Presto |
| 18. | Snowflake |
| 19. | Synapse |
| 20. | Teradata |
| 21. | Timescale DB |
| 22. | Trino |
Connection Management
To connect to a datastore, users must provide the required connection details, such as Host/Port or URI. These fields may vary depending on the datastore and are essential for establishing a secure and reliable connection to the target database.
For demonstration purposes, we have selected the Snowflake connector.
Option I: Create a Datastore with a New Connection
If the toggle for Add New Connection is turned on, this will prompt you to add and configure the source datastore from scratch without using existing connection details.
Step 1: Select any connector (as we are selecting the Snowflake connector) from the dropdown list and add connection properties such as Secrets Management, host, port, username, and password, along with datastore properties like catalog, database, etc.
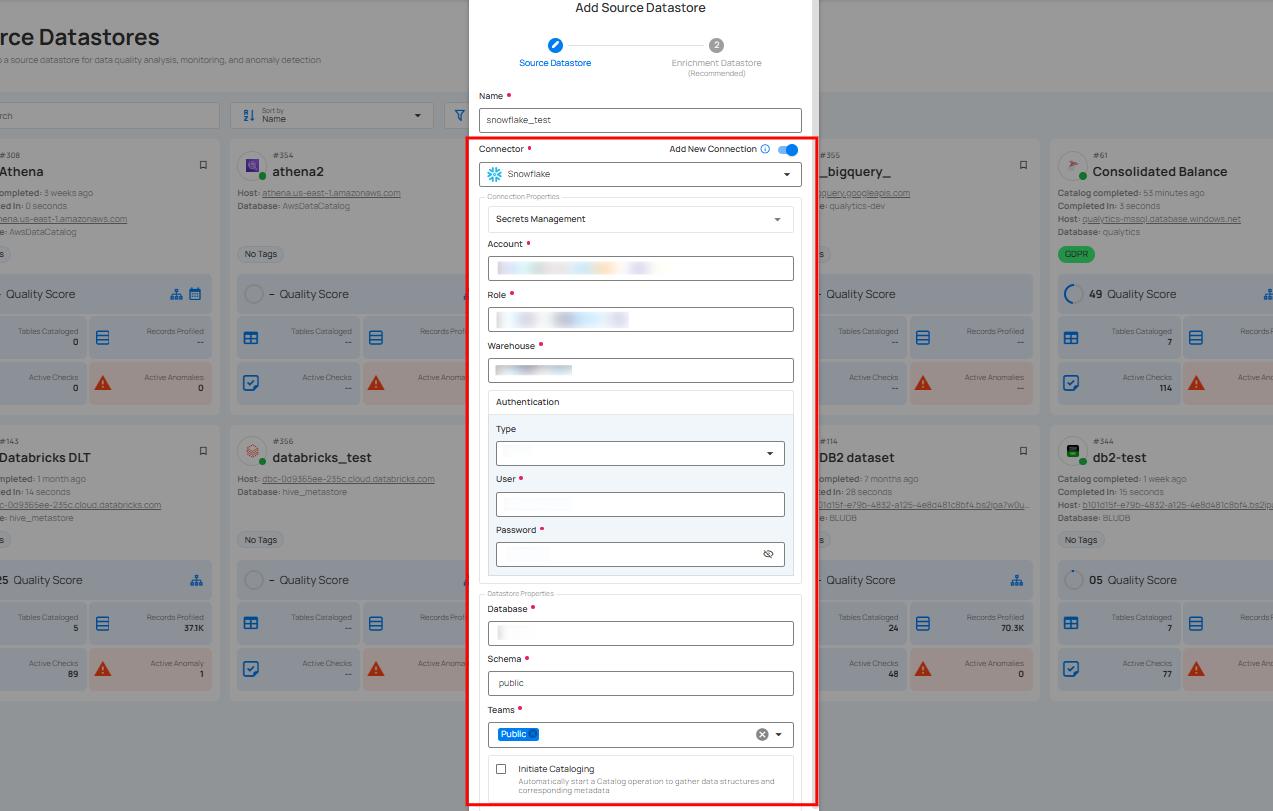
For the next steps, refer to the "Add Source Datastore" section in the Snowflake Datastore documentation.
Once a datastore is verified and created, it appears in your source datastores.
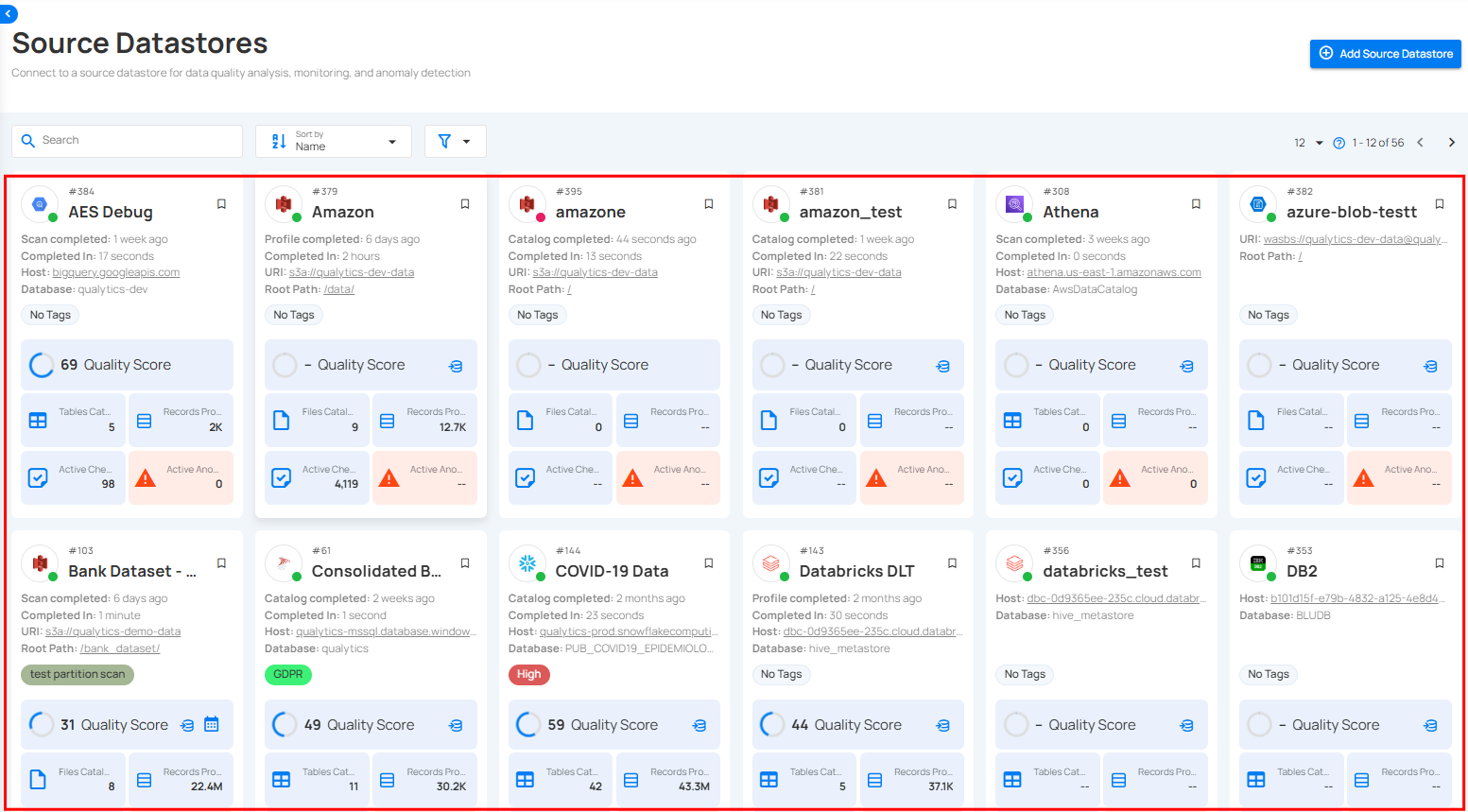
Datastore Operations
Once a datastore is added in Qualytics, you can perform three key operations to manage and ensure data quality effectively:
1. Catalog Operation
This operation imports named data collections such as tables, views, and files into the source datastore. It identifies incremental fields for scans and allows you to recreate or delete containers, streamlining data organization and enhancing discovery.
For more details about the catalog operation, refer to the "Catalog Operation" document.
2. Profile Operation
After cataloging, the Profile Operation analyzes each record within the collections to assess and improve data quality. By generating detailed metadata and interacting with the Qualytics Inference Engine, it identifies quality issues and refines checks for maintaining data integrity.
For more details about the profile operation, refer to the "Profile Operation" document.
3. Scan Operation
Finally, the Scan Operation enforces data quality checks on the collections. It identifies anomalies at the record and schema levels, highlights structural issues, and records all findings for further analysis. Flexible options allow for incremental scans, specific table/file scans, and scheduling future scans.
For more details about the scan operation, refer to the "Scan Operation" document.
By performing these operations sequentially, you can efficiently manage and ensure the quality of your data in Qualytics.
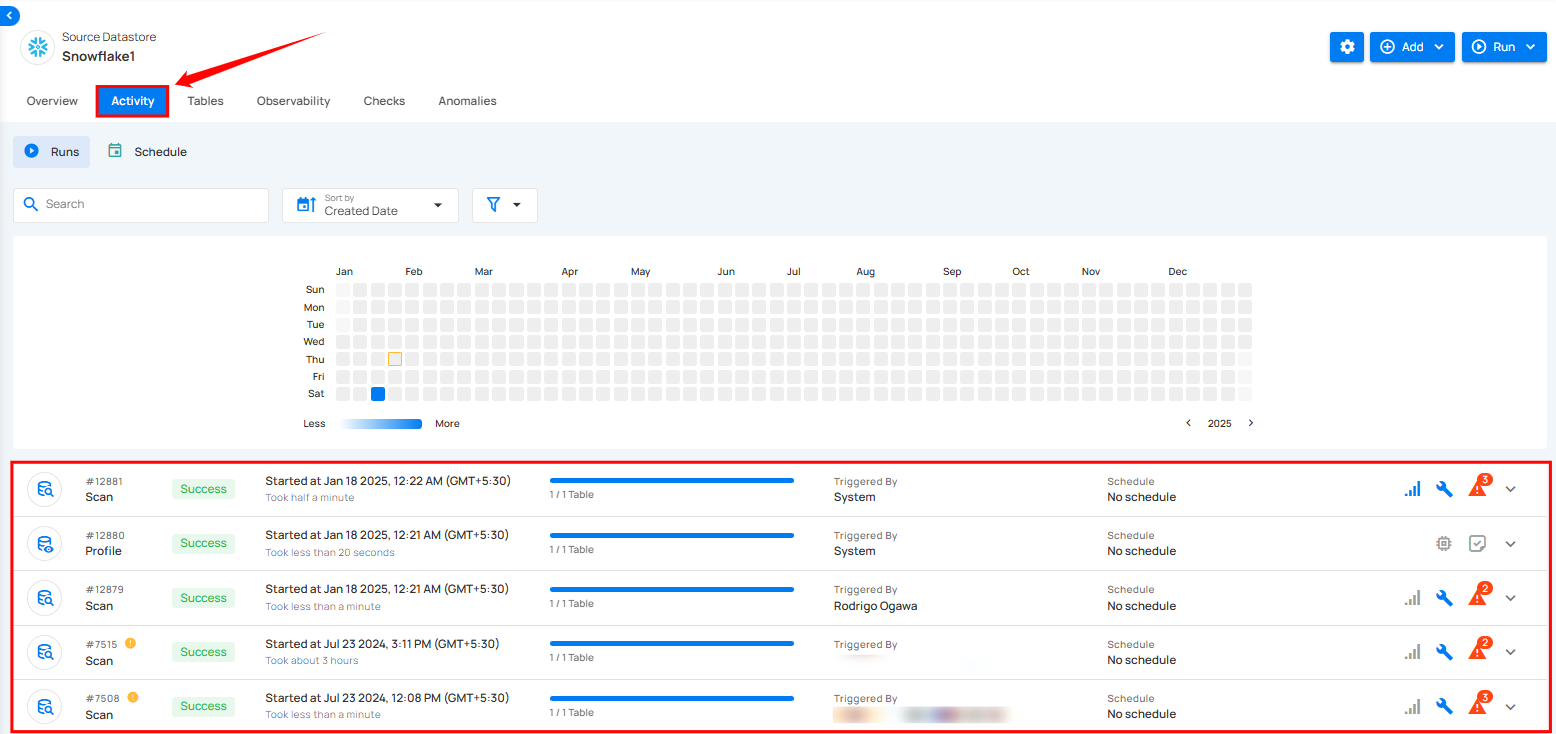
View Operation
Once the datastores are connected, you can run operations on the selected datastore. To track the progress, simply navigate to the Activity tab, where you can view the running operation.
Step 1: Simply click to open the datastore on which you ran the operation.
Step 2: After clicking on the datastore, select the "Activity" tab to view the ongoing operation.